We have n jobs, where every job is scheduled to be done from startTime[i] to endTime[i], obtaining a profit of profit[i].
You're given the startTime, endTime and profit arrays, return the maximum profit you can take such that there are no two jobs in the subset with overlapping time range.
If you choose a job that ends at time X you will be able to start another job that starts at time X.
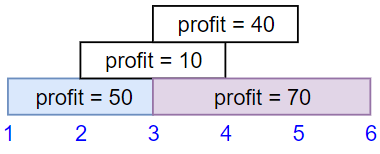
Example 1:
Input: startTime = [1,2,3,3], endTime = [3,4,5,6], profit = [50,10,40,70]
Output: 120
Explanation: The subset chosen is the first and fourth job.
Time range [1-3]+[3-6] , we get profit of 120 = 50 + 70.
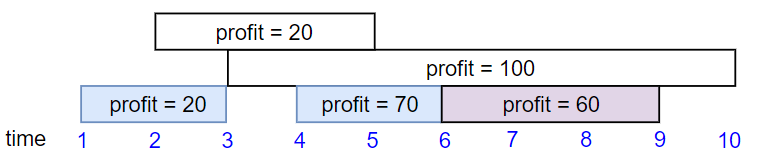
Example 2:
Input: startTime = [1,2,3,4,6], endTime = [3,5,10,6,9], profit = [20,20,100,70,60]
Output: 150
Explanation: The subset chosen is the first, fourth and fifth job.
Profit obtained 150 = 20 + 70 + 60.
First, we sort the jobs by start time in ascending order, then design a function $dfs(i)$ to represent the maximum profit that can be obtained starting from the $i$-th job. The answer is $dfs(0)$.
The calculation process of function $dfs(i)$ is as follows:
For the $i$-th job, we can choose to do it or not. If we don't do it, the maximum profit is $dfs(i + 1)$; if we do it, we can use binary search to find the first job that starts after the end time of the $i$-th job, denoted as $j$, then the maximum profit is $profit[i] + dfs(j)$. We take the larger of the two. That is:
$$
dfs(i)=\max(dfs(i+1),profit[i]+dfs(j))
$$
Where $j$ is the smallest index that satisfies $startTime[j] \ge endTime[i]$.
In this process, we can use memoization search to save the answer of each state to avoid repeated calculations.
The time complexity is $O(n \times \log n)$, where $n$ is the number of jobs.
We can also change the memoization search in Solution 1 to dynamic programming.
First, sort the jobs, this time we sort by end time in ascending order, then define $dp[i]$, which represents the maximum profit that can be obtained from the first $i$ jobs. The answer is $dp[n]$. Initialize $dp[0]=0$.
For the $i$-th job, we can choose to do it or not. If we don't do it, the maximum profit is $dp[i]$; if we do it, we can use binary search to find the last job that ends before the start time of the $i$-th job, denoted as $j$, then the maximum profit is $profit[i] + dp[j]$. We take the larger of the two. That is:
$$
dp[i+1] = \max(dp[i], profit[i] + dp[j])
$$
Where $j$ is the largest index that satisfies $endTime[j] \leq startTime[i]$.
The time complexity is $O(n \times \log n)$, where $n$ is the number of jobs.