Given strings s1, s2, and s3, find whether s3 is formed by an interleaving of s1 and s2.
An interleaving of two strings s and t is a configuration where s and t are divided into n and msubstrings respectively, such that:
s = s1 + s2 + ... + sn
t = t1 + t2 + ... + tm
|n - m| <= 1
The interleaving is s1 + t1 + s2 + t2 + s3 + t3 + ... or t1 + s1 + t2 + s2 + t3 + s3 + ...
Note:a + b is the concatenation of strings a and b.
Example 1:
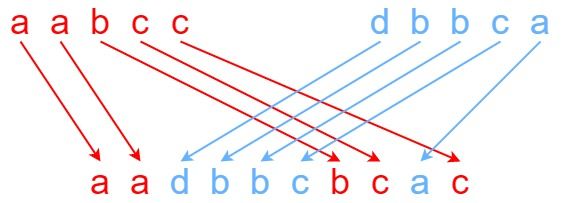
Input: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac"
Output: true
Explanation: One way to obtain s3 is:
Split s1 into s1 = "aa" + "bc" + "c", and s2 into s2 = "dbbc" + "a".
Interleaving the two splits, we get "aa" + "dbbc" + "bc" + "a" + "c" = "aadbbcbcac".
Since s3 can be obtained by interleaving s1 and s2, we return true.
Example 2:
Input: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbbaccc"
Output: false
Explanation: Notice how it is impossible to interleave s2 with any other string to obtain s3.
Example 3:
Input: s1 = "", s2 = "", s3 = ""
Output: true
Constraints:
0 <= s1.length, s2.length <= 100
0 <= s3.length <= 200
s1, s2, and s3 consist of lowercase English letters.
Follow up: Could you solve it using only O(s2.length) additional memory space?
Solutions
Solution 1: Memoization Search
Let's denote the length of string \(s_1\) as \(m\) and the length of string \(s_2\) as \(n\). If \(m + n \neq |s_3|\), then \(s_3\) is definitely not an interleaving string of \(s_1\) and \(s_2\), so we return false.
Next, we design a function \(dfs(i, j)\), which represents whether the remaining part of \(s_3\) can be interleaved from the \(i\)th character of \(s_1\) and the \(j\)th character of \(s_2\). The answer is \(dfs(0, 0)\).
The calculation process of function \(dfs(i, j)\) is as follows:
If \(i \geq m\) and \(j \geq n\), it means that both \(s_1\) and \(s_2\) have been traversed, so we return true.
If \(i < m\) and \(s_1[i] = s_3[i + j]\), it means that the character \(s_1[i]\) is part of \(s_3[i + j]\). Therefore, we recursively call \(dfs(i + 1, j)\) to check whether the next character of \(s_1\) can match the current character of \(s_2\). If it can match, we return true.
Similarly, if \(j < n\) and \(s_2[j] = s_3[i + j]\), it means that the character \(s_2[j]\) is part of \(s_3[i + j]\). Therefore, we recursively call \(dfs(i, j + 1)\) to check whether the next character of \(s_2\) can match the current character of \(s_1\). If it can match, we return true.
Otherwise, we return false.
To avoid repeated calculations, we can use memoization search.
The time complexity is \(O(m \times n)\), and the space complexity is \(O(m \times n)\). Here, \(m\) and \(n\) are the lengths of strings \(s_1\) and \(s_2\) respectively.
implSolution{#[allow(dead_code)]pubfnis_interleave(s1:String,s2:String,s3:String)->bool{letn=s1.len();letm=s2.len();ifs1.len()+s2.len()!=s3.len(){returnfalse;}letmutrecord=vec![vec![-1;m+1];n+1];Self::dfs(&mutrecord,n,m,0,0,&s1.chars().collect(),&s2.chars().collect(),&s3.chars().collect(),)}#[allow(dead_code)]fndfs(record:&mutVec<Vec<i32>>,n:usize,m:usize,i:usize,j:usize,s1:&Vec<char>,s2:&Vec<char>,s3:&Vec<char>,)->bool{ifi>=n&&j>=m{returntrue;}ifrecord[i][j]!=-1{returnrecord[i][j]==1;}// Set the initial valuerecord[i][j]=0;letk=i+j;// Let's try `s1` firstifi<n&&s1[i]==s3[k]&&Self::dfs(record,n,m,i+1,j,s1,s2,s3){record[i][j]=1;}// If the first approach does not succeed, let's then try `s2`ifrecord[i][j]==0&&j<m&&s2[j]==s3[k]&&Self::dfs(record,n,m,i,j+1,s1,s2,s3){record[i][j]=1;}record[i][j]==1}}
We can convert the memoization search in Solution 1 into dynamic programming.
We define \(f[i][j]\) to represent whether the first \(i\) characters of string \(s_1\) and the first \(j\) characters of string \(s_2\) can interleave to form the first \(i + j\) characters of string \(s_3\). When transitioning states, we can consider whether the current character is obtained from the last character of \(s_1\) or the last character of \(s_2\). Therefore, we have the state transition equation:
where \(f[0][0] = \textit{true}\) indicates that an empty string is an interleaving string of two empty strings.
The answer is \(f[m][n]\).
The time complexity is \(O(m \times n)\), and the space complexity is \(O(m \times n)\). Here, \(m\) and \(n\) are the lengths of strings \(s_1\) and \(s_2\) respectively.
We notice that the state \(f[i][j]\) is only related to the states \(f[i - 1][j]\), \(f[i][j - 1]\), and \(f[i - 1][j - 1]\). Therefore, we can use a rolling array to optimize the space complexity, reducing the original space complexity from \(O(m \times n)\) to \(O(n)\).