An undirected graph of n nodes is defined by edgeList, where edgeList[i] = [ui, vi, disi] denotes an edge between nodes ui and vi with distance disi. Note that there may be multiple edges between two nodes.
Given an array queries, where queries[j] = [pj, qj, limitj], your task is to determine for each queries[j] whether there is a path between pj and qjsuch that each edge on the path has a distance strictly less thanlimitj .
Return a boolean arrayanswer, where answer.length == queries.lengthand the jthvalue of answeris true if there is a path for queries[j] is true, and false otherwise.
Example 1:
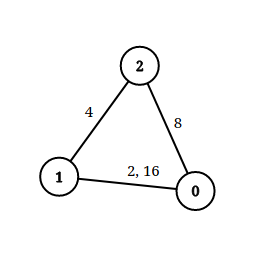
Input: n = 3, edgeList = [[0,1,2],[1,2,4],[2,0,8],[1,0,16]], queries = [[0,1,2],[0,2,5]]
Output: [false,true]
Explanation: The above figure shows the given graph. Note that there are two overlapping edges between 0 and 1 with distances 2 and 16.
For the first query, between 0 and 1 there is no path where each distance is less than 2, thus we return false for this query.
For the second query, there is a path (0 -> 1 -> 2) of two edges with distances less than 5, thus we return true for this query.
Example 2:
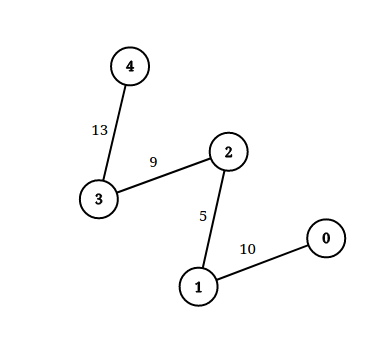
Input: n = 5, edgeList = [[0,1,10],[1,2,5],[2,3,9],[3,4,13]], queries = [[0,4,14],[1,4,13]]
Output: [true,false]
Explanation: The above figure shows the given graph.
Constraints:
2 <= n <= 105
1 <= edgeList.length, queries.length <= 105
edgeList[i].length == 3
queries[j].length == 3
0 <= ui, vi, pj, qj <= n - 1
ui != vi
pj != qj
1 <= disi, limitj <= 109
There may be multiple edges between two nodes.
Solutions
Solution 1: Offline Queries + Union-Find
According to the problem requirements, we need to judge each query \(queries[i]\), that is, to determine whether there is a path with edge weight less than or equal to \(limit\) between the two points \(a\) and \(b\) of the current query.
The connectivity of two points can be determined by a union-find set. Moreover, since the order of queries does not affect the result, we can sort all queries in ascending order by \(limit\), and also sort all edges in ascending order by edge weight.
Then for each query, we start from the edge with the smallest weight, add all edges with weights strictly less than \(limit\) to the union-find set, and then use the query operation of the union-find set to determine whether the two points are connected.
The time complexity is \(O(m \times \log m + q \times \log q)\), where \(m\) and \(q\) are the number of edges and queries, respectively.
implSolution{#[allow(dead_code)]pubfndistance_limited_paths_exist(n:i32,edge_list:Vec<Vec<i32>>,queries:Vec<Vec<i32>>,)->Vec<bool>{letmutdisjoint_set:Vec<usize>=vec![0;nasusize];letmutans_vec:Vec<bool>=vec![false;queries.len()];letmutq_vec:Vec<usize>=vec![0;queries.len()];// Initialize the setforiin0..n{disjoint_set[iasusize]=iasusize;}// Initialize the q_vecforiin0..queries.len(){q_vec[i]=i;}// Sort the q_vec based on the query limit, from the lowest to highestq_vec.sort_by(|i,j|queries[*i][2].cmp(&queries[*j][2]));// Sort the edge_list based on the edge weight, from the lowest to highestletmutedge_list=edge_list.clone();edge_list.sort_by(|i,j|i[2].cmp(&j[2]));letmutedge_idx:usize=0;forq_idxin&q_vec{lets=queries[*q_idx][0]asusize;letd=queries[*q_idx][1]asusize;letlimit=queries[*q_idx][2];// Construct the disjoint setwhileedge_idx<edge_list.len()&&edge_list[edge_idx][2]<limit{Solution::union(edge_list[edge_idx][0]asusize,edge_list[edge_idx][1]asusize,&mutdisjoint_set,);edge_idx+=1;}// If the parents of s & d are the same, this query should be `true`// Otherwise, the current query is `false`ans_vec[*q_idx]=Solution::check_valid(s,d,&mutdisjoint_set);}ans_vec}#[allow(dead_code)]pubfnfind(x:usize,d_set:&mutVec<usize>)->usize{ifd_set[x]!=x{d_set[x]=Solution::find(d_set[x],d_set);}returnd_set[x];}#[allow(dead_code)]pubfnunion(s:usize,d:usize,d_set:&mutVec<usize>){letp_s=Solution::find(s,d_set);letp_d=Solution::find(d,d_set);d_set[p_s]=p_d;}#[allow(dead_code)]pubfncheck_valid(s:usize,d:usize,d_set:&mutVec<usize>)->bool{letp_s=Solution::find(s,d_set);letp_d=Solution::find(d,d_set);p_s==p_d}}
Union-Find is a tree-like data structure that, as the name suggests, is used to handle some disjoint set merge and query problems. It supports two operations:
Find: Determine which subset an element belongs to. The time complexity of a single operation is \(O(\alpha(n))\).
Union: Merge two subsets into one set. The time complexity of a single operation is \(O(\alpha(n))\).
Here, \(\alpha\) is the inverse Ackermann function, which grows extremely slowly. In other words, the average running time of its single operation can be considered a very small constant.
Below is a common template for Union-Find, which needs to be mastered proficiently. Where:
n represents the number of nodes.
p stores the parent node of each point. Initially, the parent node of each point is itself.
size only makes sense when the node is an ancestor node, indicating the number of points in the set where the ancestor node is located.
find(x) function is used to find the ancestor node of the set where \(x\) is located.
union(a, b) function is used to merge the sets where \(a\) and \(b\) are located.