You are given a string text. You should split it to k substrings (subtext1, subtext2, ..., subtextk) such that:
subtexti is a non-empty string.
The concatenation of all the substrings is equal to text (i.e., subtext1 + subtext2 + ... + subtextk == text).
subtexti == subtextk - i + 1 for all valid values of i (i.e., 1 <= i <= k).
Return the largest possible value of k.
Example 1:
Input: text = "ghiabcdefhelloadamhelloabcdefghi"
Output: 7
Explanation: We can split the string on "(ghi)(abcdef)(hello)(adam)(hello)(abcdef)(ghi)".
Example 2:
Input: text = "merchant"
Output: 1
Explanation: We can split the string on "(merchant)".
Example 3:
Input: text = "antaprezatepzapreanta"
Output: 11
Explanation: We can split the string on "(a)(nt)(a)(pre)(za)(tep)(za)(pre)(a)(nt)(a)".
Constraints:
1 <= text.length <= 1000
text consists only of lowercase English characters.
Solutions
Solution 1: Greedy + Two Pointers
We can start from both ends of the string, looking for the shortest, identical, and non-overlapping prefixes and suffixes:
If such prefixes and suffixes cannot be found, then the entire string is treated as a segmented palindrome, and the answer is incremented by \(1\);
If such prefixes and suffixes are found, then this prefix and suffix are treated as a segmented palindrome, and the answer is incremented by \(2\), then continue to find the prefixes and suffixes of the remaining string.
The proof of the above greedy strategy is as follows:
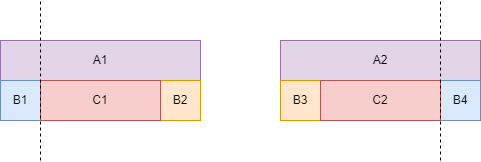
Suppose there is a prefix \(A_1\) and a suffix \(A_2\) that meet the conditions, and there is a prefix \(B_1\) and a suffix \(B_4\) that meet the conditions. Since \(A_1 = A_2\) and \(B_1=B_4\), then \(B_3=B_1=B_4=B_2\), and \(C_1 = C_2\). Therefore, if we greedily split \(B_1\) and \(B_4\), then the remaining \(C_1\) and \(C_2\), and \(B_2\) and \(B_3\) can also be successfully split. Therefore, we should greedily choose the shortest identical prefix and suffix to split, so that in the remaining string, more segmented palindromes may be split.
The time complexity is \(O(n^2)\), and the space complexity is \(O(n)\) or \(O(1)\). Here, \(n\) is the length of the string.
String hash is to map a string of any length to a non-negative integer, and its collision probability is almost \(0\). String hash is used to calculate the hash value of a string and quickly determine whether two strings are equal.
Therefore, based on Solution 1, we can use the method of string hash to compare whether two strings are equal in \(O(1)\) time.
The time complexity is \(O(n)\), and the space complexity is \(O(n)\). Here, \(n\) is the length of the string.