
题目描述
系统中存在 n 个进程,形成一个有根树结构。给你两个整数数组 pid 和 ppid ,其中 pid[i] 是第 i 个进程的 ID ,ppid[i] 是第 i 个进程的父进程 ID 。
每一个进程只有 一个父进程 ,但是可能会有 一个或者多个子进程 。只有一个进程的 ppid[i] = 0 ,意味着这个进程 没有父进程 。
当一个进程 被杀掉 的时候,它所有的子进程和后代进程都要被杀掉。
给你一个整数 kill 表示要杀掉进程的 ID ,返回被杀掉的进程的 ID 列表。可以按 任意顺序 返回答案。
示例 1:
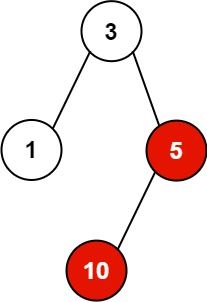
输入:pid = [1,3,10,5], ppid = [3,0,5,3], kill = 5
输出:[5,10]
解释:涂为红色的进程是应该被杀掉的进程。
示例 2:
输入:pid = [1], ppid = [0], kill = 1
输出:[1]
提示:
n == pid.lengthn == ppid.length1 <= n <= 5 * 1041 <= pid[i] <= 5 * 1040 <= ppid[i] <= 5 * 104- 仅有一个进程没有父进程
pid 中的所有值 互不相同- 题目数据保证
kill 在 pid 中
解法
方法一:DFS
我们先根据 \(pid\) 和 \(ppid\) 构建出图 \(g\),其中 \(g[i]\) 表示进程 \(i\) 的所有子进程。然后从进程 \(kill\) 开始,进行深度优先搜索,即可得到所有被杀掉的进程。
时间复杂度 \(O(n)\),空间复杂度 \(O(n)\)。其中 \(n\) 是进程的数量。
1
2
3
4
5
6
7
8
9
10
11
12
13 | class Solution:
def killProcess(self, pid: List[int], ppid: List[int], kill: int) -> List[int]:
def dfs(i: int):
ans.append(i)
for j in g[i]:
dfs(j)
g = defaultdict(list)
for i, p in zip(pid, ppid):
g[p].append(i)
ans = []
dfs(kill)
return ans
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | class Solution {
private Map<Integer, List<Integer>> g = new HashMap<>();
private List<Integer> ans = new ArrayList<>();
public List<Integer> killProcess(List<Integer> pid, List<Integer> ppid, int kill) {
int n = pid.size();
for (int i = 0; i < n; ++i) {
g.computeIfAbsent(ppid.get(i), k -> new ArrayList<>()).add(pid.get(i));
}
dfs(kill);
return ans;
}
private void dfs(int i) {
ans.add(i);
for (int j : g.getOrDefault(i, Collections.emptyList())) {
dfs(j);
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 | class Solution {
public:
vector<int> killProcess(vector<int>& pid, vector<int>& ppid, int kill) {
unordered_map<int, vector<int>> g;
int n = pid.size();
for (int i = 0; i < n; ++i) {
g[ppid[i]].push_back(pid[i]);
}
vector<int> ans;
function<void(int)> dfs = [&](int i) {
ans.push_back(i);
for (int j : g[i]) {
dfs(j);
}
};
dfs(kill);
return ans;
}
};
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | func killProcess(pid []int, ppid []int, kill int) (ans []int) {
g := map[int][]int{}
for i, p := range ppid {
g[p] = append(g[p], pid[i])
}
var dfs func(int)
dfs = func(i int) {
ans = append(ans, i)
for _, j := range g[i] {
dfs(j)
}
}
dfs(kill)
return
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | function killProcess(pid: number[], ppid: number[], kill: number): number[] {
const g: Map<number, number[]> = new Map();
for (let i = 0; i < pid.length; ++i) {
if (!g.has(ppid[i])) {
g.set(ppid[i], []);
}
g.get(ppid[i])?.push(pid[i]);
}
const ans: number[] = [];
const dfs = (i: number) => {
ans.push(i);
for (const j of g.get(i) ?? []) {
dfs(j);
}
};
dfs(kill);
return ans;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25 | use std::collections::HashMap;
impl Solution {
pub fn kill_process(pid: Vec<i32>, ppid: Vec<i32>, kill: i32) -> Vec<i32> {
let mut g: HashMap<i32, Vec<i32>> = HashMap::new();
let mut ans: Vec<i32> = Vec::new();
let n = pid.len();
for i in 0..n {
g.entry(ppid[i]).or_insert(Vec::new()).push(pid[i]);
}
Self::dfs(&mut ans, &g, kill);
ans
}
fn dfs(ans: &mut Vec<i32>, g: &HashMap<i32, Vec<i32>>, i: i32) {
ans.push(i);
if let Some(children) = g.get(&i) {
for &j in children {
Self::dfs(ans, g, j);
}
}
}
}
|